
第五次推进会里,技术同事已经把一周的差评、投诉和巡店记录做成了异常聚类看板。
这一回,会没有再卡在“准不准”。
大家真正开始讨论的,是更往下一层的事:
- 这 17 条问题里,今天谁先接
- 哪几条必须升区域
- 店长改完以后,回写到哪里
- 督导下次巡店时,怎么知道这条问题是真改了,还是只是群里回了句“已关注”
也就是从这一次开始,这个项目才真正往前走。
因为 AI 做完分析之后,下一步不是再做一张更聪明的报表。
下一步是把分析结果接进经营系统。
以下案例做了匿名处理,品牌名、城市和门店数做了模糊化,但推进顺序、组织冲突和执行动作都保持原样。
先把“进入经营系统”这件事定义清楚
很多团队一提“让 AI 进入经营系统”,脑子里先出现的是一个大平台。
真实项目里不是这样。
在连锁餐饮里,经营系统往往不是一个页面,而是一串默认会发生的动作:
谁触发 -> 谁确认 -> 谁接单 -> 多久要改 -> 改完回到哪里 -> 下周怎么复盘
如果 AI 只停在“发现问题”“标记风险”“生成摘要”,它还只是分析层。
只有当它输出的每一条判断,最后都能变成一张有人接、有时限、有回写、能复盘的任务卡,它才算真的进入经营系统。
这篇不再讨论“为什么进不去”。
这篇只讲一件事:
我们是怎么把 AI 分析结果,一步一步接进总部、区域、门店的真实动作链。
这个案例来自一家 70-100 店量级、区域化管理的连锁餐饮品牌。这个量级下,我们用了三周把第一条链接起来。门店更少的品牌通常会更快,组织层级更复杂的品牌会更慢,但顺序基本一致。
下面这张总览图,对应后面要展开的 6 个环节。

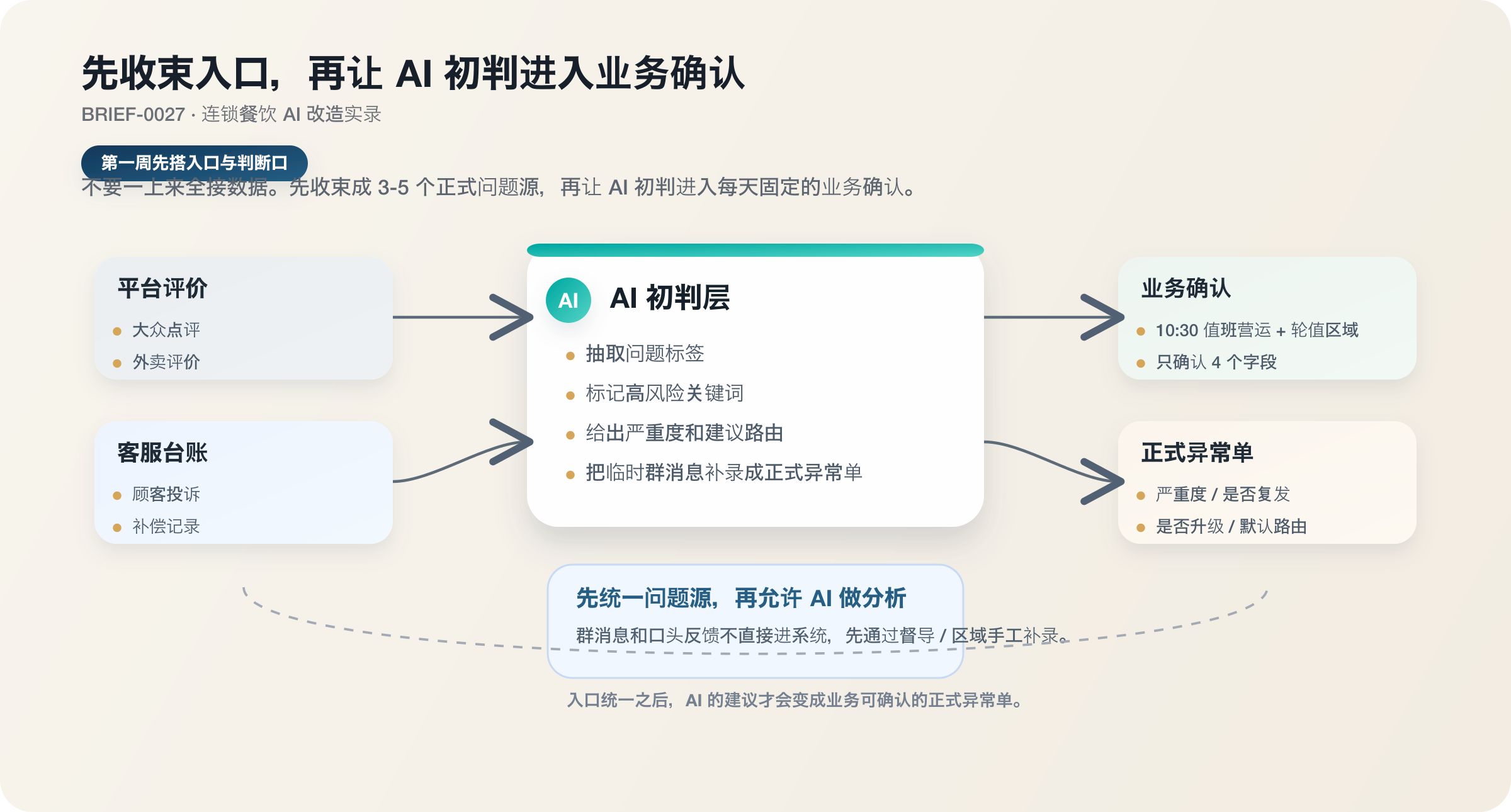
第一步:先收束成一条正式问题链,不要一上来全接
这个项目一开始就做了一个很重要的取舍:
不做“大而全”的 AI 经营平台,先只接一条问题链。
我们选的是:
差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写
原因很简单,这条链同时满足 4 个条件:
- 高频,门店每天都在遇到
- 跨层,会经过总部、区域、门店三层
- 有成本,处理慢了会直接影响口碑和复购
- 容易验收,能看见有没有超时、有没有复发、有没有关闭
真正开始接系统前,我们先把正式问题源缩到 4 个:
- 平台差评和外卖评价
- 客服投诉台账
- 巡店记录
- 门店日报异常
门店群消息和口头反馈先不直接进系统。
不是因为它们不重要,而是第一阶段太散、太口语、责任边界也不清楚。我们最后的折中做法是:
督导或区域经理可以把群里的临时异常,手工补录成一条正式异常单。
这一步看起来很基础,但它决定了后面所有动作能不能对上。
因为如果入口不统一,AI 后面所有“智能分析”都只是在替一部分世界做总结。剩下那部分真正影响经营的异常,还是留在群里和会议口头里。
第二步:AI 先做初判,但进入经营系统前要过一次业务确认
技术侧第一轮很快就做出了三个能力:
- 把差评和投诉按问题类型聚类
- 标记高风险门店和高风险关键词
- 给出建议优先级和建议路由
这一步不难。
真正关键的是,分析结果不能直接变成派工指令。
在真实组织里,它要先过一次业务确认。
我们定下来的做法是:
每天早上 10:30 之前,总部营运值班和当天轮值的区域经理一起过一遍高风险清单。每条问题只确认 4 个字段:
- 严重度是否成立
- 是否属于复发
- 是否需要升级
- 默认路由是否接受
注意,这一层不是让业务团队重新写分析。
AI 已经把摘要、标签和建议路由都准备好了,业务只需要做确认或改写。
为了让这件事能积累成系统资产,我们还要求所有 override 都必须选原因,第一版只保留 5 个选项:
- AI 误判严重度
- 真实场景信息不足
- 需要按组织惯例特殊处理
- 问题归属判断错误
- 已在线下提前解决
这个设计有两个实际作用。
第一,它让业务团队更容易接受 AI。
因为系统不是在越级指挥,而是在给出一份可以被确认的建议。
第二,它让技术团队拿到了有价值的反馈。
以后再看模型,不是听一句“这个不太准”,而是能看到哪种误判最多、哪类问题总被人工改路由。
第三步:把分析结果翻译成任务卡,而不是翻译成报表
很多 AI 项目做到这里,还是容易停在总部 dashboard。
但经营系统真正需要的,不是“这条问题很重要”,而是“这条问题现在归谁”。
所以第二周我们先补的,不是模型参数,而是一张路由表。
| 问题类型 | 默认 owner | 时限 | 升级条件 |
|---|---|---|---|
| 单次服务态度、漏单、出餐慢 | 店长 | 当班或 24 小时内 | 同店 7 天内重复出现,升区域 |
| 连续复发的出品质量问题 | 区域经理 | 24 小时内认领,48 小时内回写 | 超时或再次复发,升总部营运 |
| 食安、异物、公开扩散风险 | 总部专项负责人 | 2 小时内认领 | 同步区域和客服,进入专项跟进 |
从这一刻开始,AI 输出不再只是“一个判断”,而是落到了某个具体的人和一个明确的时间承诺上。
一位区域经理在第二周复盘时说得很直白:
我不是怕多一张表,我是怕问题都挂在总部看板上,最后还是我在群里一个个追。现在至少系统先把该追哪几条给我钉住了。
这句话很关键。
因为它说明,AI 真正进入经营系统,不是生成更多信息,而是把追问题这件事先钉到 owner 身上。
还有一个特别现实的决定,我们当时没有要求区域经理和店长去登录一个新 AI 后台。
第一版真正落地的方式,是把任务卡推到他们已经在用的地方:
- 区域群收到异常摘要和任务链接
- 在线台账里出现待认领任务
- 督导巡店表能看到本店未关闭问题
这是现场落地里最容易被忽略的一件事。
门店不会因为 AI 很先进就改变习惯。门店只会在问题进入它原来就会看的地方时,才真正接住。

第四步:给任务卡补齐动作模板,不让它停在“看懂了”
如果系统只告诉店长:
“本店本周服务态度差评偏高。”
这还只是 insight,不是经营动作。
所以第三步之后,我们马上补的是任务卡模板。也就是说,让系统知道一条问题被接住后,下一步至少要生成什么动作。
每张任务卡都统一带 5 个字段:
- 问题摘要
- 默认 owner
- 截止时间
- 建议动作模板
- 回写要求
动作模板不写空话,只写当前组织真的会执行的动作。
比如一条“漏单 + 顾客等待过久”的问题卡,第一版动作模板通常是:
- 当班复盘出餐环节
- 确认是否为备料或交接问题
- 店长在当天班后会说明纠偏动作
- 次日高峰前复查一次
如果是服务类问题,模板就会更偏向:
- 明确当班责任人
- 补做服务话术提醒
- 如涉及顾客补偿,补录处理结果
- 次周巡店抽查同类问题
如果是食安或异物风险,模板就不能再停在门店自查,而要直接进入:
- 总部专项负责人认领
- 区域同步到店
- 当班证据留存
- 处理结果和复检节点写回系统
这一步的核心不是做一套很完整的 SOP 手册。
而是让 AI 输出的分析结果,第一次长出一个“下一步要做什么”的标准骨架。
第五步:把回写做轻,但必须做结构化
到这里,门店最容易出现的阻力通常不是“不愿意改”,而是“又多了一层填表”。
所以回写层不能设计得太重。
我们的第一版最后只强制 4 个字段:
- 处理人
- 处理时间
- 处理动作
- 处理结果
照片、聊天截图、培训记录这些都先做成可选,不强推。
原因很现实。
第一阶段最重要的,不是建立完美证据链,而是先把“动作发生过”这件事稳定写回系统。
但只让门店自己回写也不够。
所以我们又补了一个角色:区域复核
高风险问题或复发问题,不能由门店自己直接点关闭,必须由区域经理或督导做一次复核,确认这条问题是:
- 已处理
- 暂时缓解
- 无效整改,需要再次打开
这个设计一加上去,系统第一次开始有了“整改质量”,而不是只有“整改数量”。
也就是说,AI 分析进入经营系统,不是停在发现问题,而是连“改没改、改得好不好”都开始进入结构化记录。
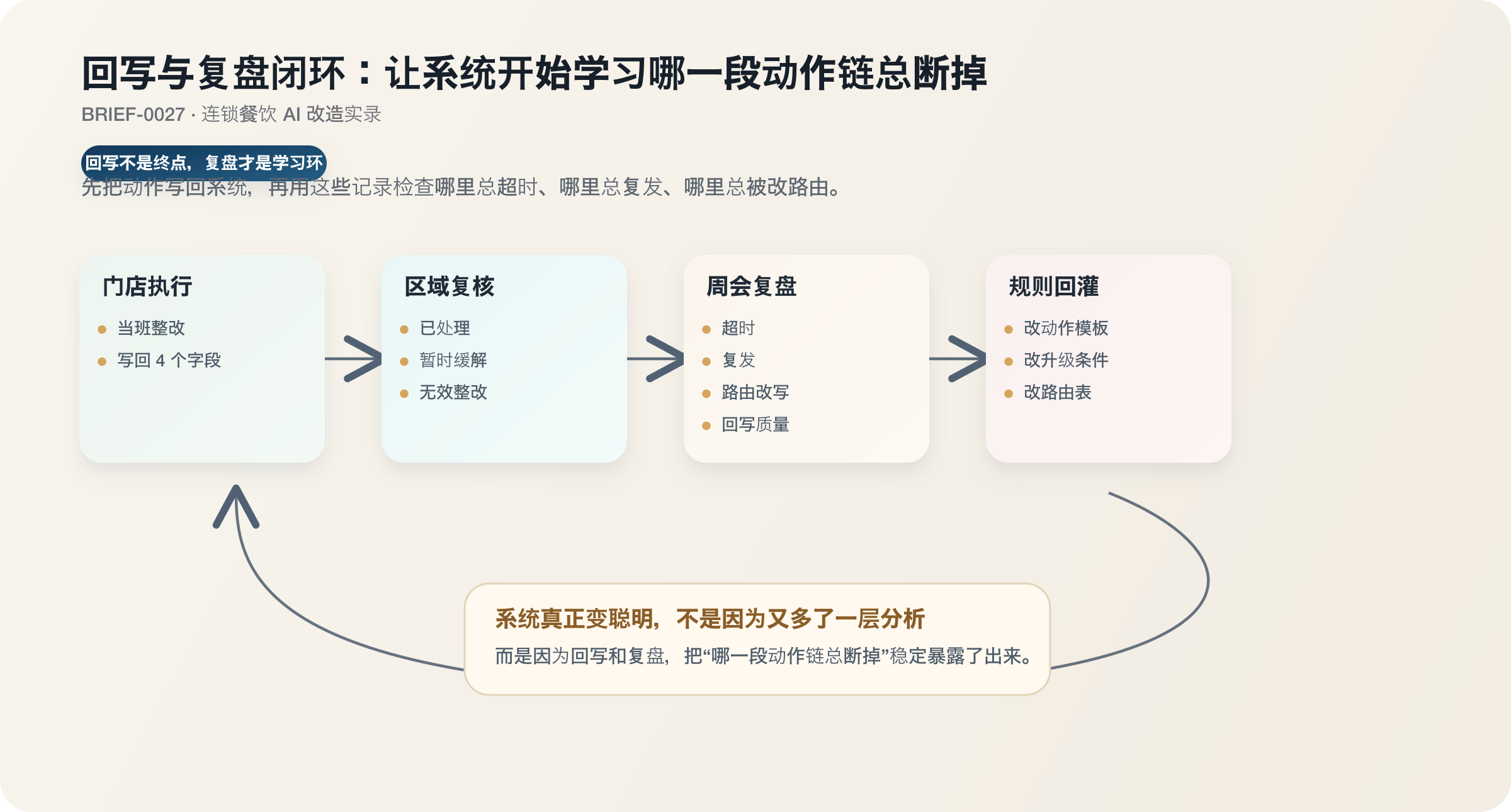
但回写本身还不是终点。
回写只是把动作发生过这件事稳定写回系统,真正让系统开始变聪明的,是用这些记录去检查哪一段动作链总断掉。
第六步:周会不再只看异常数量,而是看哪一段动作链总断掉
很多团队会把“每周复盘”理解成最后再做一张经营周报。
真实项目里,复盘不是用来总结 AI 多聪明,而是用来检查哪一段动作链总断掉。
所以第三周开始,我们把周一复盘会的看法改了。
以前大家看的是:
- 本周差评多少
- 哪类问题增加
- 哪些店异常更多
后来只看 4 件事:
- 哪些问题超时还没人接
- 哪些问题已经关闭,但 7-14 天内再次出现
- 哪些问题 AI 和人工经常判断不一致
- 哪些门店整改动作很多,但回写质量很差
这时候 AI 的角色才终于对了。
它不是替管理层做最终判断,而是替大家把“哪一段动作链没有走完”提前拎出来。
我们在第三周就看到一个很典型的模式。
表面上看,很多差评都被写成“服务态度问题”。
但把回写和复发记录串起来后发现,同一批门店的问题几乎都集中在晚高峰、交接班和备餐拥堵时段。
这说明很多被表面归类为“态度问题”的投诉,底层其实是排班和出餐节奏问题。
如果没有前面的任务卡、回写和复盘,这个判断永远出不来。
你只能一直在标签层打转。
如果你现在就要开始,可以按这个执行方案落第一轮
如果你今天就在做一个餐饮 AI 试点,我建议第一轮不要追求“全店、全链、全系统”。
直接按下面这套顺序开做。
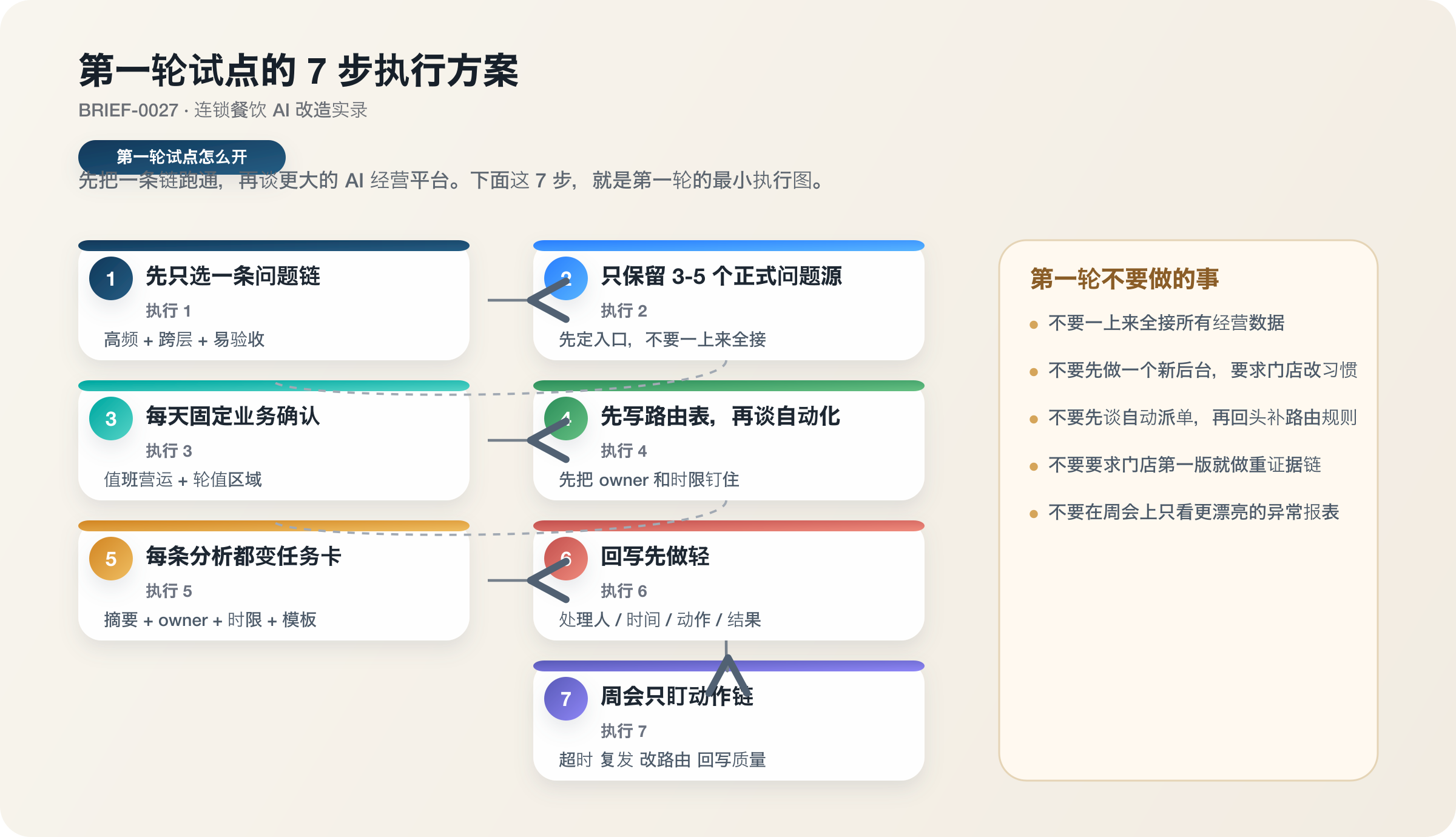
执行 1:先只选一条问题链
不要同时接差评、排班、损耗、采购、会员、客诉全链。
先选一条高频、跨层、容易验收的链。最常见的起点就是:
差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写
执行 2:只保留 3-5 个正式问题源
第一轮不要什么都接。
先定清楚:
- 哪些入口算正式问题源
- 哪些入口先不进系统
- 谁有权把线下问题补录成正式异常
执行 3:给 AI 结果加一道每天固定的业务确认
固定一个时点,最好就是每天上午。
让总部营运值班和轮值区域一起看高风险清单,只确认 4 件事:
- 严重度
- 是否复发
- 是否升级
- 路由是否接受
执行 4:先写一张路由表,再谈自动化
不要先问模型能不能自动派单。
先把高频问题写成:
- 默认 owner 是谁
- 时限是多少
- 什么条件下要升级
没有这张表,后面所有自动化都会漂。
执行 5:把每条分析结果都变成任务卡
任务卡最少带 5 个字段:
- 摘要
- owner
- 时限
- 动作模板
- 回写要求
如果一条分析结果最后还只是停在周报里,它就还没有进入经营系统。
执行 6:回写先做轻,不要一上来做重
第一版先强制:
- 处理人
- 处理时间
- 处理动作
- 处理结果
证据类字段先放后面。
你最先要建立的是稳定回写,不是完美留痕。
执行 7:每周复盘只盯动作链,不盯漂亮报表
第一轮周会只看:
- 超时
- 复发
- 路由改写
- 回写质量
只要把这四类看清楚,你就知道下一周规则该改哪里。
最后一句话
AI 分析之后进入经营系统,不是再做一张更大的看板。
而是把每一条分析结果,稳定地翻译成一张有人接、有时限、有动作模板、有回写、能复盘的任务卡。
在连锁餐饮里,这件事真正依赖的,也不是一个万能模型。
它依赖的是总部、区域、门店之间,先把同一条问题要怎么流转、怎么关闭、怎么复发、怎么复盘这套动作链写出来。
只有这条链写出来了,AI 才不是“会分析”。
它才是真的进入经营系统。