如果最近有哪件事,最能说明连锁餐饮为什么必须把 差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写 做成一条真实的经营链,可能就是 2025 年 9 月 罗永浩和贾国龙 / 西贝那场风波。
2025 年 9 月 10 日,罗永浩公开质疑西贝“预制”“还卖得贵”;随后几天,品牌和创始人用起诉、开后厨、“罗永浩菜单”这些更强硬的动作回应。到后面行业评论和媒体复盘再回头看,真正值得行业记住的,已经不是谁在舆论场里更能吵,而是一次外部质疑,能不能被企业迅速吸收成内部动作。
因为对连锁餐饮来说,真正危险的从来不是有人公开吐槽。
真正危险的是:顾客情绪已经冲进公共舆论场,企业内部却还没有完成分级、没有找到该接的人、没有形成整改动作,也没有把结果回写进系统。这样一来,组织最后只能一边解释,一边被动挨打。
后面媒体披露,西贝风波后连夜复盘,重新去做产品现做、价格调整和食安表达。这个后半段,反而最值得做餐饮的人记住。因为真正有价值的,从来不是第一时间的口水仗,而是后面的整改链有没有真的跑起来。
第一篇里,我写了我们怎么把连锁餐饮想象中的 AI店长,拆回成一串真实的营运动作。
第一篇讲怎么拆。
这一篇讲,拆完之后,第一仗到底打哪里。
但真实项目往前走一步,难题其实才刚开始:
如果第一次试点只能先打一仗,这一仗到底从哪里开打?
最近,我们和一家连锁餐饮企业做前期诊断时,第二次会谈几乎整场都在回答这个问题。
为了保护客户,下面继续不写品牌名,也不写精确门店数,只保留对判断有用的细节。
那次会前,我们没有让团队准备新的“AI 场景大全”,只要求把同一周里最容易引发争论的 4 份材料带上桌:
- 近 7 天的差评 / 投诉样本
- 最近一次巡店整改表
- 一次节假日前后的排班调整记录
- 一次补货 / 缺货异常记录
第一篇里,我们用这些材料看清了 3 处断点:总部排不出优先级,区域升级口径不稳,门店做了动作但总部收不到回写。
这一篇只讲后半段,也就是项目真正开始排优先级的那一步:
当这 3 处断点都被看见以后,我们为什么没有先做排班、补货或巡店平台,而是把第一仗收口到 差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写。

图 1:第二次会谈里,我们真正要决定的不是“AI 能做什么”,而是“哪条链最适合先打赢”。
第二次会谈里,白板上摆着 4 条候选链
那天白板上,真正被拉出来比较的,不止一条链:
差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写巡店问题 -> 定责 -> 整改 -> 验收 -> 回写排班建议 -> 店长确认 -> 执行调整补货 / 订货建议 -> 门店确认 -> 异常预警
这 4 条都重要。
但第一次试点不能按“哪个更高级”来选,也不能按“哪个老板最容易兴奋”来选。
我们当时先把场景判断收成了 4 个问题,而且这 4 个问题都很实际,不是写给 PPT 的,是写给项目能不能在 4-6 周 内活下来的:
- 这条链是不是几乎每天都在发生
- 它会不会天然横跨总部、区域、门店三层
- 它的升级、路由、完成口径能不能先写成一页纸
- 如果先跑一个小范围试点,晨会和区域跟进里能不能比较快看出变化
后来我们回头再看小红书上那些高频的“客诉处理 6 步”“差评申诉模板”“恶评回复模版”,其实只是进一步印证了一件事:
顾客反馈在真实餐饮语境里,本来就不是偶发问题,而是一条每天都在重复发生的流程问题。

图 2:第一次试点真正该比的,不是概念大小,而是这条链能不能先形成可验收的闭环。
4 条候选链,是怎么一条条被筛掉的
排班没有先赢,不是因为它不重要
排班当然重要。
但我们把那份节假日前后的排班调整记录摊开时,很快就看到它为什么不适合当第一仗:
- 客流波动、出勤变化、岗位搭配和店长临场修正,全缠在一张表里
- 同样一条建议,店长采不采纳,常常不只取决于建议本身
- 如果 2 周后效果不好,很难第一时间说清楚,到底是建议错了,还是现场变量太多
也就是说,排班不是不能做。
而是它一上来就会把项目带进预测精度、店长采纳率、数据质量这些更重的验证里。
第一次试点如果一开始就进这么深,项目很容易在“到底算不算成功”这里卡住。
补货没有先赢,是因为责任链太长
补货也一样。
我们看一份补货 / 缺货异常记录时,几乎立刻就会碰到这些问题:
- 缺货到底是销量波动、门店盘点偏差,还是上游供给节奏问题
- 同样是废损偏高,责任该落在店里、区域,还是供应链
- 就算给出建议,门店有没有按建议执行,也未必能很快被验证
所以补货的难点不是没有价值。
而是第一阶段一旦把它放进来,项目很容易从一条经营闭环,变成一场跨供应链、采购、营运和门店执行的系统工程。
这对第一次试点来说,链太长了。
巡店整改,其实是我们认真比较过的第二顺位
真正和投诉链拉得最近的,其实不是排班和补货,而是巡店整改。
因为它也很贴近现场,也能牵动总部、区域和门店。
但它还有一个更现实的门槛:
巡店记录往往散在照片、手写表、群消息和不同督导各自的模板里,第一阶段如果先把它当主入口,团队很快就会先死在口径统一和结构化上。
但我们把巡店表和那周的顾客反馈放在一起看,最后还是把它放到了第二阶段,原因有 3 个。
第一,投诉链有外部压力,启动刚性更强。
顾客已经把问题抛出来了,团队不能假装没看见。
而巡店问题在项目早期更容易被解释成“先放一下,下一轮再看”。
第二,投诉链的起点和终点都更清楚。
它天然就要回答:
- 这条问题要不要升级
- 谁来接
- 多久没回写算超时
- 是否已经形成整改动作
而巡店记录在早期更容易碰到主观口径不一致的问题:不同督导看到的是不是同一件事,同一问题是不是一定要升级,现场和总部未必是一个标准。
第三,投诉链更容易先追复发。
同一家店、同一类问题、短时间内反复出现,管理层会立刻意识到这不是客服小事,而是营运问题。
所以我们的判断从来不是“巡店不重要”。
而是:
第一次先把投诉闭环跑顺,让顾客反馈成为主入口;巡店记录先作为辅助证据,第二阶段再并进来。
最后帮我们拍板的,其实是一条匿名差评
那次会谈真正让团队统一判断的,不是一页功能清单,而是一条匿名化样本。
评价内容大概是这样:
等了 35 分钟,少上了一份菜,提醒后店员态度还很冲。
如果没有一条真正的经营链,这条评价大概率只会变成两件事:
- 门店先回复一句道歉
- 总部第二天多看到一条差评
但我们把这条评价拿回那周的材料里对照,问题就变了。
因为它不是孤立的一句话。
一旦再往前后看一步,就会发现它至少同时碰到了 3 类经营信号:
- 出餐慢
- 漏单 / 交接问题
- 服务态度失控
如果这家店过去几天还在巡店记录里出现过后厨交接或出餐秩序问题,这条反馈就不该再停留在客服层。
它应该真正流过 5 个节点:
- 抓取问题
- 做严重度分级
- 判断该留在门店、升级区域,还是同步总部
- 生成标准整改动作
- 回写结果,并标记是否可能复发
那次会谈里,我们还现场手工做过一次合并模拟:
把这条差评和同店前几天的巡店记录并在一起,原本散在两张表里的问题,最后被收成同一个区域 owner 的后厨交接整改项。
第一阶段真正要验证的,不是系统做了多少功能。
而是这种“从散点评价收成统一动作”的事,能不能稳定发生。
总部最后看到的,不该只是“又来一条差评”。
而应该是:
为什么升级、谁接了、改了什么、多久没回写、这类问题是不是又在同一家店重复出现。
这也是投诉链最后胜出的关键。
它不是因为“更像 AI”才赢。
而是因为它最容易把顾客压力,翻译成总部、区域、门店都能接住的动作链。
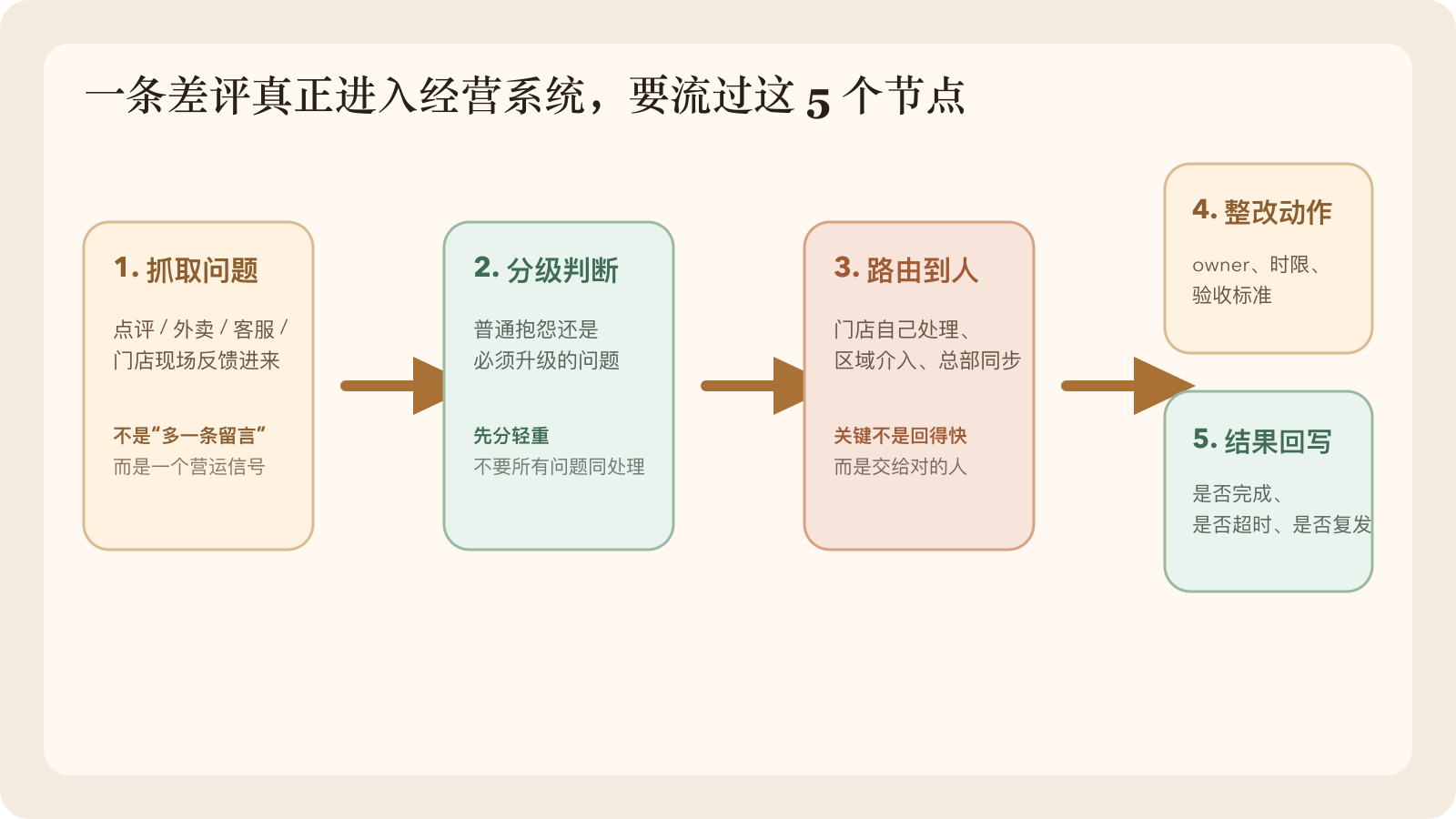
图 3:真正值得先打赢的,不是“自动回复”,而是让一条问题完整流过 5 个管理节点。
第一阶段,不是做完整平台,而是先把 3 个动作串起来
第一篇里,我们拆出了 10 个高频营运 skill。
但真实交付不会把 10 个 skill 一次全上。
真正先落地的,只有最贴着这条链的 3 个:
异常提炼分级路由整改回写
因为第一次试点最需要证明的,不是系统多完整,而是这条链有没有被明显缩短。
按我们过往前期诊断和试点推进的经验,4-6 周 是比较现实的窗口:
足够验证一条链有没有被缩短,也不至于让组织在漫长准备里失去耐心。
如果明天重来一次,我还是会按下面这个顺序推进。
第 1 周:先写一页纸规则,只选一个试点区域
第一周不要急着谈模型。
先把过去 30-90 天 的投诉、差评、客服记录拉出来,只回答 3 个问题:
- 什么问题必须升级
- 升给谁
- 多久不回写算超时
如果企业的数据还散,第一版也不要贪全。
先抓两路最容易拿到的数据就够:
- 点评 / 外卖后台里的顾客反馈
- 企业内部已经有的客服登记或投诉台账
这一步的参与人不用多:
1个营运负责人1个数据或 IT 同事1个试点区域经理
第一次试点最怕的不是工具不够强,而是第一周就拉太多人、接太多系统、开太多会。
第 2-4 周:用规则引擎和轻量提取先跑起来,保留“全量人工复核”
第二阶段再让技术工具上场。
但技术预期一定要收窄。
第一次试点更现实的做法,不是上来就做“自动判断”,而是先用 规则引擎 + 轻量文本提取 跑最小闭环:
- 从评价里提取门店、问题标签和严重词
- 命中升级规则时给出分级和路由建议
- 生成区域或总部当天该盯的异常摘要
这时候不要急着自动对外回复,也不要急着取消人工。
前两周最好保持“全量人工复核”,但前提是试点范围要收小。
我通常只会先放在一个区域、5-10 家门店里跑,让区域经理或督导每天固定花 20-30 分钟 看一遍建议结果。
第一次试点的目标不是彻底自动化,而是验证这条链到底能不能缩短。
第 5-6 周:把整改回写补上,再开始看复发
到了第三阶段,重点就不是“有没有建议”,而是:
- 谁接了
- 有没有改
- 改完有没有回写
- 同类问题是不是还在复发
这里一定要接受一个现实:
第一次试点里,门店未必会马上愿意按统一格式回写。
所以更稳的做法不是硬压门店,而是先让区域经理或督导代填最关键的 3 个字段:
owner完成时间是否复发
第一阶段里,是否复发 不追求算法精确。
先按“同店、同类问题、7-14 天 内再次出现”做区域级判断,就已经足够实用。
只要这 3 个字段开始稳定,投诉链就已经真正进入经营系统了。
整轮试点,我只会盯 4 个数
第一次试点最容易被功能清单带偏。
其实 4-6 周 里,只要盯住下面 4 个指标,就足够判断这条链值不值得继续做:
- 首次响应时间有没有缩短
- 升级和路由准确率有没有提高
- 整改超时率有没有下降
- 同类问题复发率有没有下降
如果这 4 个数开始变化,组织会比任何演示都更快理解这件事有价值。
反过来,如果这 4 个数基本没动,通常也不是一句“AI 不行”就能解释。
更常见的失败信号其实是:
- 规则写得太复杂,一线根本不愿意执行
- 总部和区域对升级标准始终没有统一
- 回写动作没有 owner,最后所有问题又回到群消息里
一旦看到这 3 个信号,不要继续加功能。
先回头把规则和责任边界收紧,再谈扩场景。
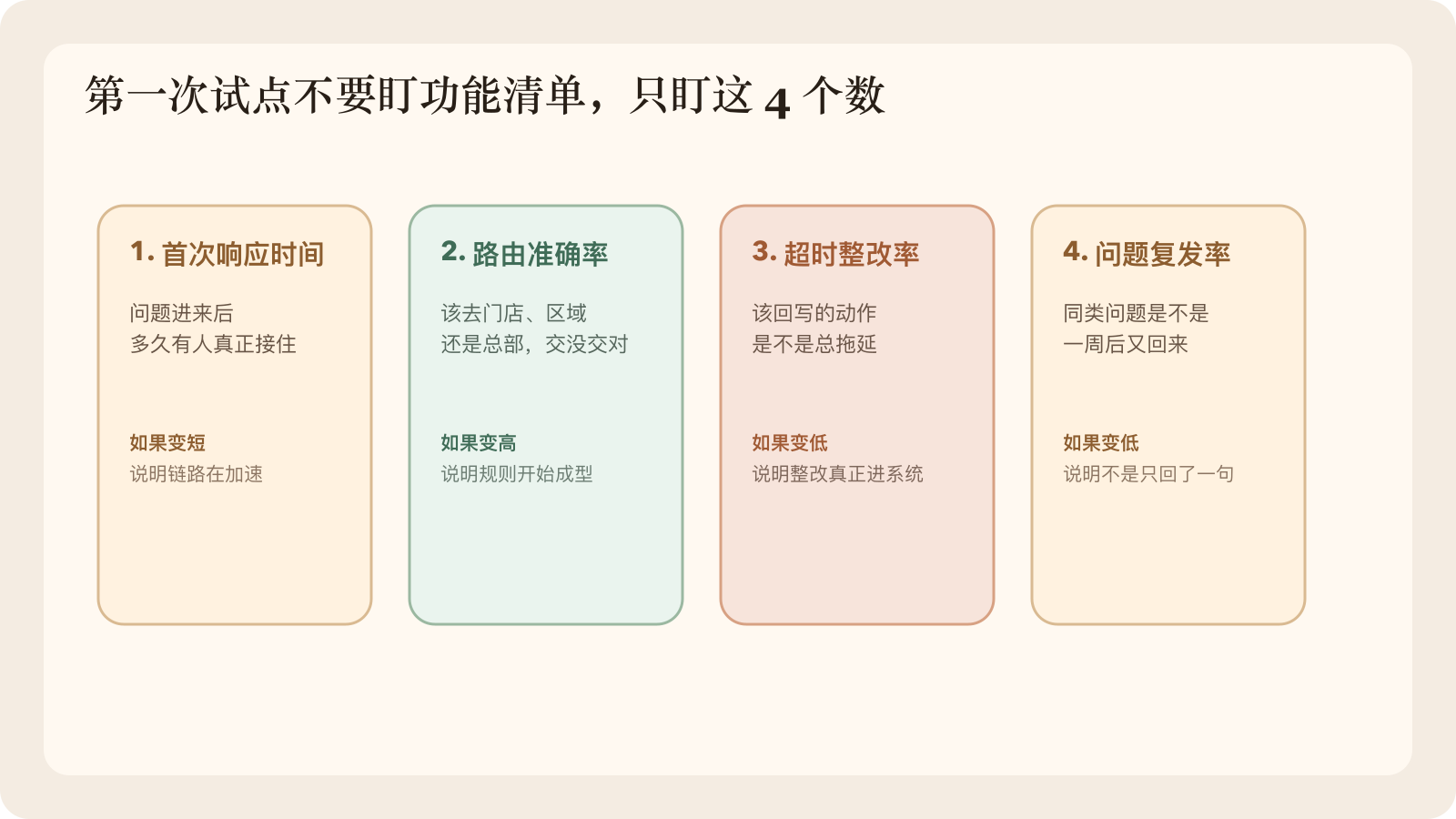
图 4:第一次试点不是做大平台,而是让 4 个关键指标先动起来。
最后一句
这就是我们最后先选投诉闭环的原因。
不是因为它最花哨,也不是因为它听起来最战略。
而是因为在真实项目里,它最容易先把总部、区域、门店都拉进同一条动作链里。
第一次试点真正该赢的,不是一个角色想象。
而是一条能被组织接住、能被指标验证、能继续往下扩的闭环:
差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写。