

智能体重塑国际物流 · 第 2 篇
一票从深圳出口到洛杉矶的电子产品,报关员拿到商业发票和装箱单之后,要在 30 分钟内完成这些动作:核对买卖双方名称和税号是否与合同一致、从几十个 HS 编码中选对那个 10 位码、确认是否需要出境许可证、计算关税和增值税、检查原产地是否触发反倾销税、把申报数据填进单一窗口——任何一个字段填错,轻则改单延误,重则移送缉私。
这不是个例。一家年处理 5000 票报关单的货代,如果差错率在行业平均的 2% 水平,意味着每年有 100 票会遭遇查验、改单或罚款。而 Flexport 用 AI 把这个数字压到了 0.2%——1000 票里只有两票出问题。
怎么做到的?AI 报关不是一个模型,是一条 8 层流水线。每一层都不可跳过,每一层的误差都会向后传播。
一、一票报关单的 30 分钟:人在做什么
传统报关流程可以拆成七个步骤。
第一步:收单。 客户发来商业发票、装箱单、提单、合同——可能是 PDF 扫描件,可能是照片,可能是 Excel。报关员第一件事是把这些文件打开,找到关键信息。
第二步:录单。 从发票中找出商品名称、数量、单价、币种、原产地、成交方式。从提单中找出起运港、目的港、船名航次、柜号。从装箱单中匹配每个 SKU 的件数、毛重、净重、体积。
第三步:归类。 这是最难的。HS 编码体系有 6 位国际通用码、5000 多个商品组,中国在 6 位基础上扩展到 10 位。一个「便携式紫外线婴儿奶瓶消毒器」——它属于「家用电器」「消毒设备」「婴儿用品」「带锂电池产品」四类——走哪个码?选错了,税率差几倍甚至触发监管条件。
第四步:校验。 监管条件是否满足?是否需要出境许可证、3C 认证、商检?原产地是否能享受协定税率?是否有反倾销税?
第五步:计税。 完税价格怎么算?运费保费怎么分摊?汇率用哪天?
第六步:申报。 填进单一窗口,提交海关系统。
第七步:应对回执。 放行还是查验?如果是查验,补什么资料?
一个有经验的报关员,最快 30 分钟完成一票。新手可能一小时。而在这个过程中,差错来自每一步——录单漏字段、归类凭经验、监管条件没查到最新版本。
二、拆开黑盒:AI 报关的 8 层流水线
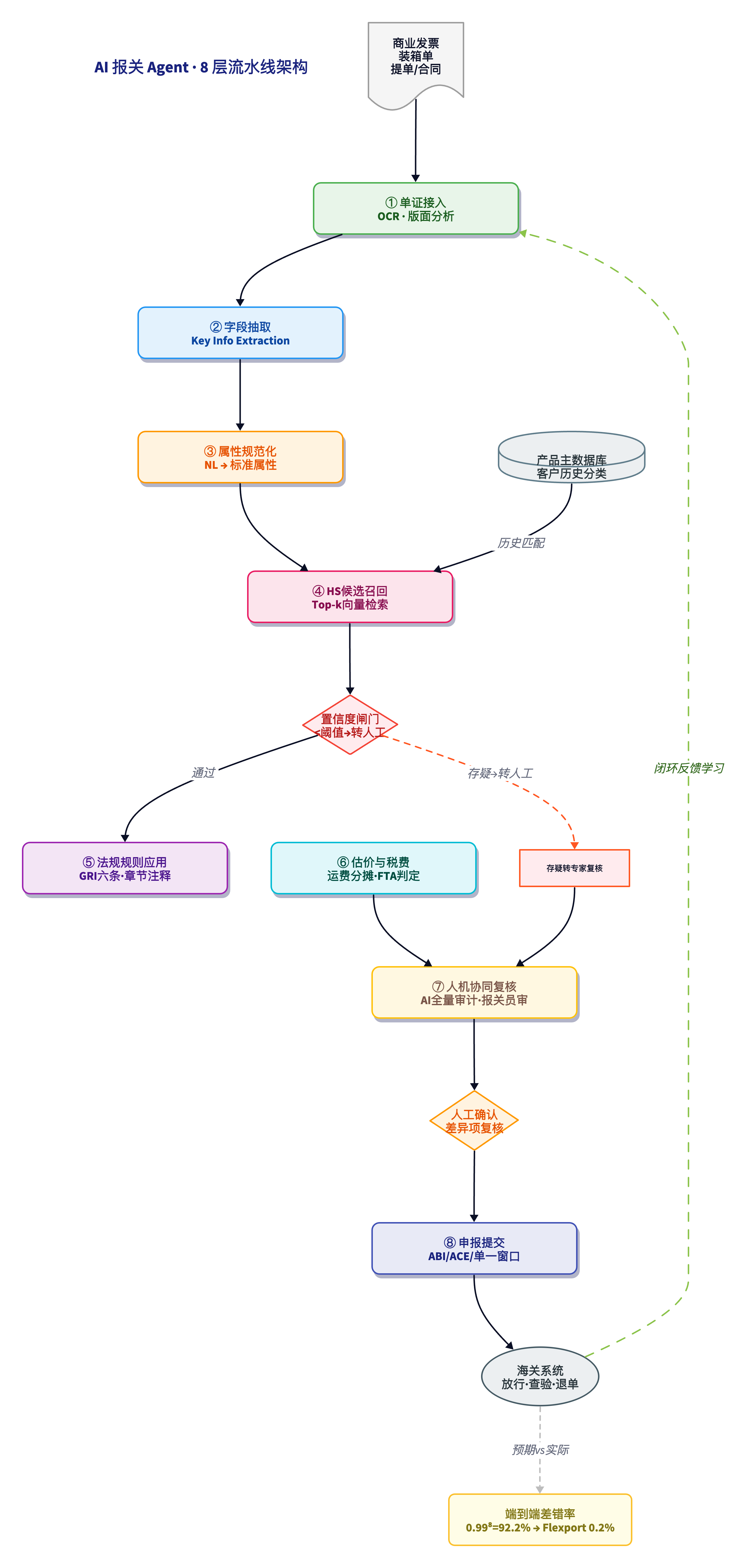
AI 报关 Agent 不是在替代某一个步骤,而是把七个步骤重新编排成 8 层流水线。每一层有明确的输入、AI 或规则组件、输出、以及典型的失败模式。
第 1 层:单证接入与 OCR。 输入是客户发来的 PDF、图片、扫描件。AI 需要版面分析:这是发票还是装箱单?表格从哪到哪?印章盖住了哪个字段?输出是结构化文本加坐标。典型失败:低分辨率扫描导致字符错误、混合中英文的发票表格被拆错行列、手写批注被忽略。
第 2 层:字段抽取。 从 OCR 结果中抽取结构化的 key-value:发票号、买卖双方、SKU 行项目、单价、币种。这层用 Key Information Extraction 模型(如 LayoutLM),但公开基准显示:在真实发票上,F1 值从 93 掉到 84 是常事——因为客户单据格式千差万别。
第 3 层:商品属性规范化。 这一层把自然语言描述映射为标准属性。发票上写「USB 充电迷你风扇」,系统需要补全为「材质=塑料+金属,用途=个人便携冷却,供电=USB 5V DC,是否含电池=是,电池类型=锂离子」。如果属性补不齐,后面 HS 归类就只能靠猜。马士基特别指出:用户搜「computer」,HS 的法律用语是「automatic data processing machines」——语义匹配在报关场景里经常失败。
第 4 层:HS 候选召回与排序。 从商品属性向量检索 Top-k HS 编码候选。广州单一窗口的「智能预归类」在这层做到前三位税号准确率 95%、前四位 90%。但到 10 位,学术界 HSCodeComp 基准中最佳 AI agent 只有 46.8% 的准确率——而人类专家是 95%。
第 5 层:法规与税则规则应用。 这不是 LLM 的自由推理,而是规则引擎的硬校验。GRI 六条归类总规则、章节注释、品目注释、本国裁定——必须按法律层级逐条适用。这层不靠概率,靠确定性代码。
第 6 层:估价与税费校验。 包括成交价格调整、运费保费分摊、原产地规则校验、FTA 优惠税率资格判定。这层出错不触发「归类错误」统计,但会直接导致多交或少交关税——同样致命。
第 7 层:人机协同复核。 AI 输出的是一个「建议包」:推荐的 HS 编码、置信度、引用的法规条文、与历史申报的差异项。报关员看着这个包做最终确认——不是从头做,而是审 AI 做得对不对。Flexport 把这一层做到了全量审计:100% 的报关单在提交前由 AI 预审并由持证报关员复核。而行业常态是事后 5-10% 抽查。
第 8 层:申报提交与反馈学习。 报关单通过 ABI/ACE/单一窗口接口提交给海关。海关回执——放行、查验、退单——作为反馈信号回流,形成持续学习的闭环。
三、误差是怎么放大的:0.99 的 8 次方是 0.92

如果忽略中间层的拦截与纠错,把 8 层流水线简化为独立串联,会得到一个用于警醒的简化模型:
假设每层准确率都是 99%——看起来很高。但 8 层串联之后,整体完全不受拦截地正确的概率是:
0.99^8 ≈ 0.922也就是说,即使每层都做到 99%,最终也只有 92.2% 的报关单完全无误——对应 7.8% 的差错率,远高于行业平均 2%。
反推 Flexport 的 0.2% 差错率:如果 8 层都需要正确,每层允许的错误率是:
1 - (1 - 0.002)^(1/8) ≈ 0.00025即每层平均只能有 0.025% 的错误率,或者说是 99.975% 的准确率。这不是靠一个模型能做到的——它要求每一层都有「置信度低于阈值就转人工」的闸门。
更准确的分析来自 HSCodeComp 基准研究中的公开数据:HS 分类准确率不能脱离「几位码、哪国扩展、商品描述质量、是否有专家复核」来讨论。韩关税局合作模型在 925 个困难子目中 Top-3 可到 93.9%;但在真实 10 位码加噪声描述的 HSCodeComp 基准中,AI 最佳仅 46.8%。这个差距说明:AI 报关的核心不是让 AI 做最终决定,而是让 AI 把「明显对」和「存疑」分开——明显对的自动过,存疑的转给专家。
四、Flexport 案例:从 2% 到 0.2% 的系统工程
Flexport 的 AI 报关架构有四个公开披露的关键组件。
第一,产品分类库。 Flexport 维护了一套覆盖其客户商品范围的产品主数据库——不是通用 HS 码表,而是「客户实际进出口的商品」与 HS 编码的映射。当新报关单进来,AI 先匹配产品库中的历史分类,而非从头推理。这大幅缩小了候选范围。
第二,全量 AI 审计。 传统报关行通常在提交后抽查 5-10% 的报关单。Flexport 在每一票提交前,由 AI auditor 做全量预审——检查字段完整性、HS 编码与商品描述的匹配度、监管条件的触发情况。2025 年 TechCrunch 报道,Flexport 一次性发布了多个 AI 工具,核心逻辑就是「不抽样,全审」。
第三,持证报关员复核。 AI 审完后,持证报关员做最终确认。这里的效率提升不在「省掉了人」,而在「人审的是 AI 整理好的差异项,不是从头读一遍」。操作时间从 30 分钟压缩到复核几个关键差异点。
第四,审计日志。 每一次 AI 建议、人工修改、最终提交的 HS 编码都被记录。Flexport 称过去 5 年通过合规自动化为客户节省了超过 9 亿美元的关税敞口——这个数字不是靠「更快」,而是靠「更少出错」。
Flexport 将差错率压到 0.2% 的密码不是单一技术突破,而是四个组件的组合:主数据先行 + 全量审计 + 人机复核 + 可追溯日志。
五、你的报关 RAG 知识库该怎么搭

报关 RAG 知识库的核心问题不是「把法规塞进向量库」,而是三个工程挑战。
版本化管理。 海关税则每年更新,监管条件随时变化,反倾销税率按月调整。知识库里必须记录每条法规的生效日期、废止日期、适用口岸。检索时必须按「申报日期」过滤有效版本——不能把去年已取消的监管条件推给报关员。
按效力分层。 法律、行政法规、海关总署公告、直属海关通知——效力不同,冲突时的优先级不同。RAG 检索结果必须标注效力层级,让报关员知道哪条是必须遵守的、哪条是参考性的。
引用溯源。 AI 给出的每一条法规建议必须附带原文出处——条文编号、发布日期、发布机关。深圳海关「查验宝典」95.3% 的准确率背后,就是这个引用溯源机制。没有引用源的 AI 建议在报关场景里不能用。
最后一个原则:规则引擎兜底。 税率计算、监管条件判定、原产地规则适用——这些是确定性计算,不应交给 LLM 的概率输出。正确架构是:LLM 负责理解、检索、建议,规则引擎负责计算和校验。
六、AI 报关的三条铁律
回头看这个 8 层流水线和每层的误差传播,有三条规则是绕不开的。
铁律一:AI 不替代人,替代人的重复劳动。 报关员真正的价值不在「录单」和「翻税则」——那是最容易被 AI 替代的部分。报关员的价值在「这票货要不要走这个编码」「这个监管条件会不会触发查验」「客户这个描述是不是在回避某个税号」。AI 报关的目标是把录单和初筛的时间从 30 分钟压到 3 分钟,让报关员把精力放在判断上。
铁律二:不跳过规则引擎。 关税计算、监管条件判定、原产地规则——这些是确定性计算。LLM 给建议,规则引擎做校验,不能反过来。Flexport 的 0.2% 差错率、中国海关 62 个智能模型,没有一个是纯 LLM 端到端——它们都有规则引擎兜底。
铁律三:不留没有审计日志的 AI 决策。 每一项 AI 建议——HS 编码推荐、监管条件判断、税率计算——必须记录在案。人工修改了什么、为什么改——也必须记录。当海关来查时,能拿出一条完整的决策链路:「AI 建议→人工复核→修改原因→最终申报」。这不是「信任 AI」,是「AI 辅助 + 人负责 + 日志可查」。
这是「智能体重塑国际物流」系列的第二篇。第一篇《300 万次 AI 任务、0.2% 差错率》建立了全貌,本篇拆开了其中最关键的一环。下一篇将聚焦 AI 如何在运价和采购环节重塑国际货运定价——从 4 小时到 5 分钟。
参考来源
- Flexport 0.2% 差错率、9 亿美元关税敞口节省:Flexport 官方博客及 TechCrunch 2025 报道
- WCO & 海关总署 2025 年《中国海关人工智能和机器学习实地调研报告》
- HSCodeComp 基准(46.8% AI 准确率)、韩关税局合作模型(93.9% Top-3)
- 广州单一窗口「智能预归类」、深圳海关「查验宝典」、湛江海关「AI 审单」、广州「智慧审证」相关数据:海关总署及地方海关公开信息