最近,我们和一家连锁餐饮企业连续做了几轮 AI 落地前期诊断。
为了保护客户,下面不写品牌名,也不写精确门店数,只保留对判断有用的细节:
这是一家已经跨区域开店、总部有日报系统、巡店机制和顾客反馈入口的连锁团队。
第一轮会前,我们没有让团队准备一份“AI 规划 PPT”。
我们只让他们带 4 样东西来开会:
- 前一天晨会还在追的门店清单
- 近 7 天的差评 / 投诉样本
- 最近一次巡店整改表
- 一次节假日前后的人力调整记录
原因很简单。
如果 AI 真的要落进经营系统,第一步该做什么,答案通常不藏在概念里,而藏在这些最真实的材料里。
但第一次会谈一开始,桌上冒出来的还是几个很大的词:
AI店长营运 Copilot总部智能中台门店助手
这些词都不算错。
问题在于,一旦把材料摊开来看,我们很快就发现,这家企业真正缺的并不是一个“更聪明的角色”。
真正反复卡住他们的,是下面这些事:
- 总部每天能看到很多报表,但晨会前还是说不清今天先盯哪几家店
- 差评和投诉每天都在进来,但严重程度、责任归属、升级标准并不一致
- 区域经理接到很多碎片信息,却很难迅速判断先追哪一件
- 巡店发现的问题不少,可整改动作经常断在微信群、Excel 和口头交代里
所以我们那几轮会谈里,几乎没有先聊模型。
我们先做了另一件更实际的事:
把企业最近一周真正发生过的经营问题摊开,一段段拆,看到底是哪条判断链断了。
拆到这里,我们对这类连锁餐饮企业的 AI 起点就越来越清楚了。
第一步不是先造一个 AI店长。
而是先把总部、区域、门店之间那条最常断掉的营运判断链补起来。

图 1:我们在项目里先盯住的,不是角色替代,而是“谁先看见问题、谁来分级、谁来接、谁来改、结果怎么回写”这条经营判断链。
我们进场后,先把“AI店长”拆成了三处断点
第一轮材料摊开之后,我们没有急着下方案。
我们先做了一件特别基础,但非常关键的事:
把同一周里发生的问题,按“总部怎么知道、区域怎么接、门店怎么改”重新排了一遍。
排完之后,最明显的是三处断点。
1. 总部看得见,但排不出优先级
这家企业不是没有数据。
晨会前,日报、平台反馈、门店异常、巡店结果都已经能看见。
问题在于,这些信息同时从不同入口进来:
- 有的在日报系统里
- 有的在点评 / 外卖反馈里
- 有的在巡店表里
- 有的还在群消息里
总部能看到很多问题,但没有一套稳定的方式,把它们压成“今天先盯哪几家店、先追哪类问题”的清单。
所以管理层每天都像在看很多信息,却很难快速形成同一套判断。
2. 区域接得到,但口径不稳定
第二个断点出现在区域层。
同样一条差评,有时门店自己回了就算结束,有时区域会介入,有时明明已经碰到卫生风险,却还被当作普通服务抱怨处理。
这不是因为谁不负责。
而是因为:
- 什么情况算普通投诉
- 什么情况必须升级
- 什么情况需要跨门店复盘
这些规则在真实执行里并没有被稳定写下来。
于是区域经理接到问题之后,更多还是靠经验判断。
经验丰富的人能接住,经验不足的人就会漏掉。
3. 门店做了动作,但总部收不到回写
第三个断点出现在门店闭环。
巡店问题也好,投诉整改也好,很多门店其实不是完全没动作。
真正的问题是,动作做完之后,没有统一回到总部能复盘的地方。
结果就变成:
- 事情像是处理过了
- 但没有统一回写
- 也没有形成下一轮复盘依据
总部最后只会得到一种模糊感受:
“问题很多。”
但到底哪类问题总在重复、哪家店总在超时、哪类整改总落不下去,其实说不清。
这也是为什么我们在项目里越来越确定:
所谓 AI店长,本质上是把一串本来就没拆清楚的动作,假装塞进了一个角色里。
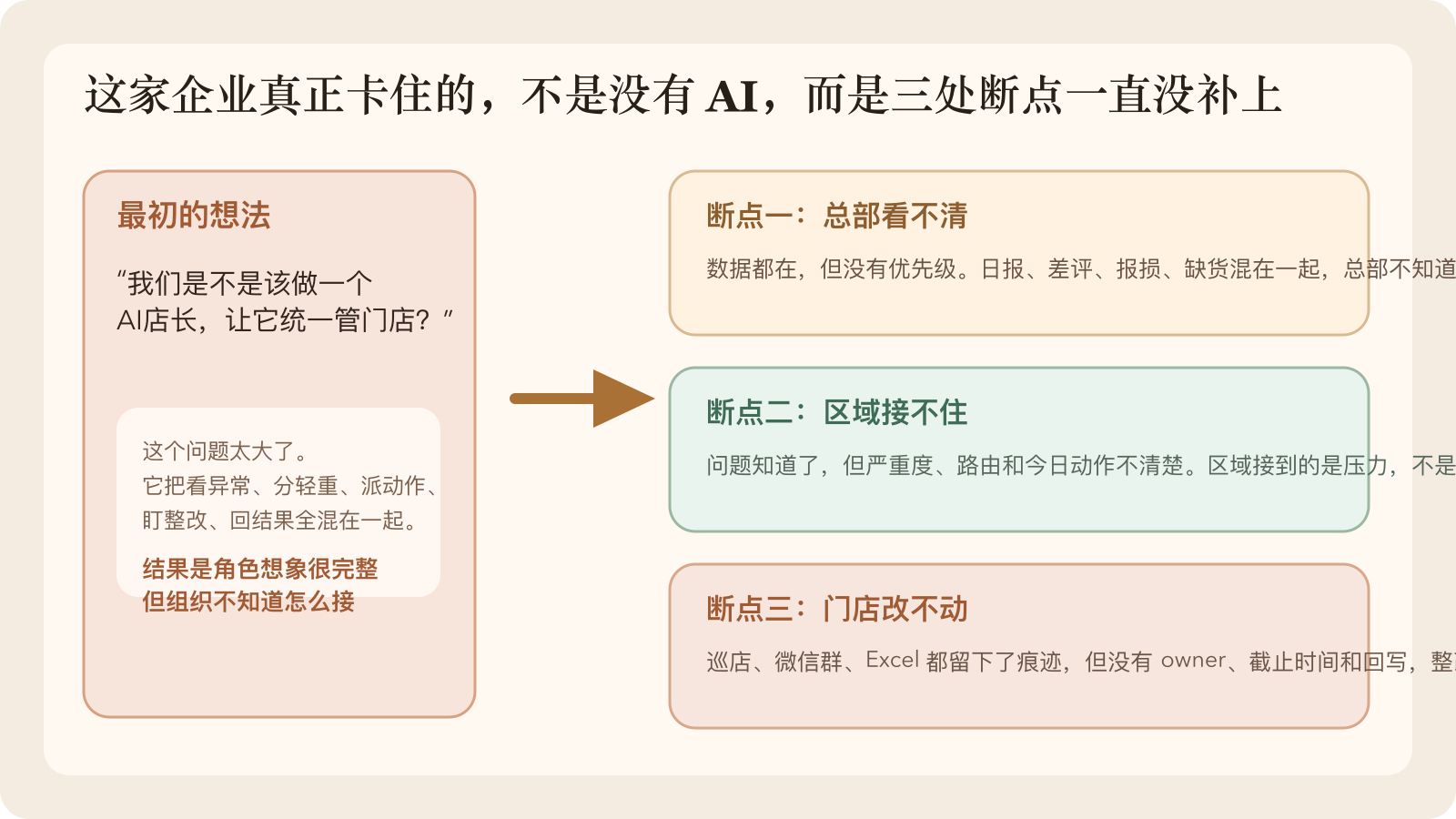
图 2:这次项目前期诊断里,我们真正看到的不是“缺一个角色”,而是总部看不清、区域接不住、门店改不动这三处断点。
我们为什么没有先做排班、补货和巡店平台
很多人会以为,既然我们已经看到这么多问题,那第一仗就该选最“高级”的场景。
但真实项目推进不是这么做的。
我们当时真正摆上桌比较过的候选链,至少有 4 条:
差评 / 投诉 -> 分级 -> 路由 -> 整改 -> 回写巡店问题 -> 定责 -> 工单 -> 验收 -> 回写排班建议 -> 门店确认 -> 执行调整补货 / 订货建议 -> 门店确认 -> 异常预警
这 4 条都重要。
但第一阶段不能靠“都重要”来做决定。
我们最后用的是一套很朴素的筛选标准:
- 这条链是不是每天都在发生
- 是不是会横跨总部、区域、门店三层
- 输入输出能不能先定义清楚
- 第一阶段能不能在
4-6 周内看到结果
按这套标准筛下来,排班和补货都没有被我们放在第一位。
不是因为它们不重要。
而是因为它们对第一阶段来说,前置条件更重。
为什么没先做排班
排班当然是高价值场景。
但它通常同时依赖这些东西:
- 历史客流和时段波动
- 门店岗位配置
- 出勤与请假数据
- 节假日前后的预测逻辑
- 店长实际排班习惯
也就是说,排班不是不能做。
而是第一阶段一上来就做,往往会很快把项目带进预测精度、数据质量、门店接受度这些更重的验证里。
为什么没先做补货
补货也很重要。
但补货链通常又会碰到:
- SKU 太多
- 废损口径不统一
- 中央厨房 / 采购节奏不同
- 缺货和过量的责任边界不清
一旦第一阶段就把补货放进来,项目很容易从“经营判断链”变成“预测系统工程”。
为什么巡店整改没有先赢
巡店整改其实是我们认真考虑过的第二顺位。
因为它也很贴近营运现场。
但它相比投诉链有两个问题:
- 频次通常没差评 / 投诉那么高
- 问题入口不如顾客反馈那么集中
也就是说,巡店整改很适合第二阶段扩,但第一仗未必最容易先跑出结果。
最后真正赢下第一顺位的,是投诉闭环。
原因不是它最“高级”。
恰恰相反,是因为它最像真实管理问题:
- 高频
- 跨层
- 离顾客最近
- 规则能先写
- 价值反馈快
而且我们后来又去看了一圈平台上的行业讨论,会更有感。
小红书上和餐饮 AI 相关的热门内容,很多都在讲海报、菜单图、点餐体验、流量物料。
但真正贴近连锁营运现场的,从来不是这些。
真正反复出现的,还是客诉模板、巡店总结、标准化检查表、人效和补货逻辑。
这反而让我们更确定:
平台上最热的餐饮 AI,不一定是企业里最该先做的。
这次诊断里,我们先圈出了 10 个高频营运 skill
在这轮项目前期诊断里,我们没有先定义“一个 AI 角色应该会什么”。
我们是反过来做的:
先问企业最近一周最反复、最耗管理精力、又还不是最终拍板的中间动作是什么。
从这些动作里,我们先圈出了 10 个最值得封装成 skill 的点。
总部层
-
日报异常提炼把散在日报、投诉、巡店里的异常压成可读摘要。 -
门店风险优先级排序不是只列问题,而是先告诉晨会今天先盯哪几家店。 -
客诉严重度分级把普通服务抱怨、复发问题、食安风险拆出不同等级。 -
复发问题识别识别同一家店、同一类问题在短时间内重复出现的情况。
区域层
-
路由建议判断这件事应该留在门店、升级到区域,还是同步总部质控。 -
区域晨会待跟进清单生成把当天必须追的店、必须追的问题整理成可执行清单。 -
巡店问题与客诉合并归因把线下巡店和线上差评里说的同类问题并成一个整改对象。
门店与闭环层
-
标准整改动作生成针对不同问题类型给出门店先执行的标准动作模板。 -
整改超时提醒发现哪些任务到了时间还没有完成或没有更新状态。 -
回写完整性检查不是只看“已处理”,而是检查结果有没有按口径回写完整。
这 10 个 skill 不是我们坐在会议室里凭空想出来的。
它们都是在真实推进里,被材料和问题一点点逼出来的。

图 3:我们这轮诊断最后不是得到一个“大角色定义”,而是反推出一组更适合先封装的高频营运 skill。
但第一阶段,我们只会先做 3 个模块
这是很多项目最容易失控的地方。
明明已经圈出了 10 个 skill,团队很容易顺势把它做成一个“大而全平台”。
但我们在真实推进里,反而会故意把第一阶段收得很小。
如果现在就开工,我们第一阶段只会先做 3 个模块:
1. 异常提炼
先把问题看清楚。
把顾客评价、平台投诉、门店反馈、巡店问题压成一条统一可读的异常摘要。
这一层至少要包含:
- 门店
- 时间
- 问题类别
- 严重程度
- 是否重复发生
2. 分级路由
先把问题交对人。
这一层不追求“像真人一样回复顾客”。
第一阶段只做一件更值钱的事:
让系统先判断这条问题该留在门店、升级到区域,还是同步总部质控。
3. 整改回写
先把闭环补上。
这一层决定项目到底有没有经营价值。
因为 AI 如果只停在“生成了一段分析”,那它还没有真正进入经营系统。
我们更关心的是:
- 谁接了这件事
- 什么时候该完成
- 有没有按标准回写
- 哪类问题在反复超时
换句话说,这一阶段不是在做一个会说话的系统。
而是在把这条判断链做短:
看见问题 -> 分清轻重 -> 找到谁接 -> 生成动作 -> 结果回写
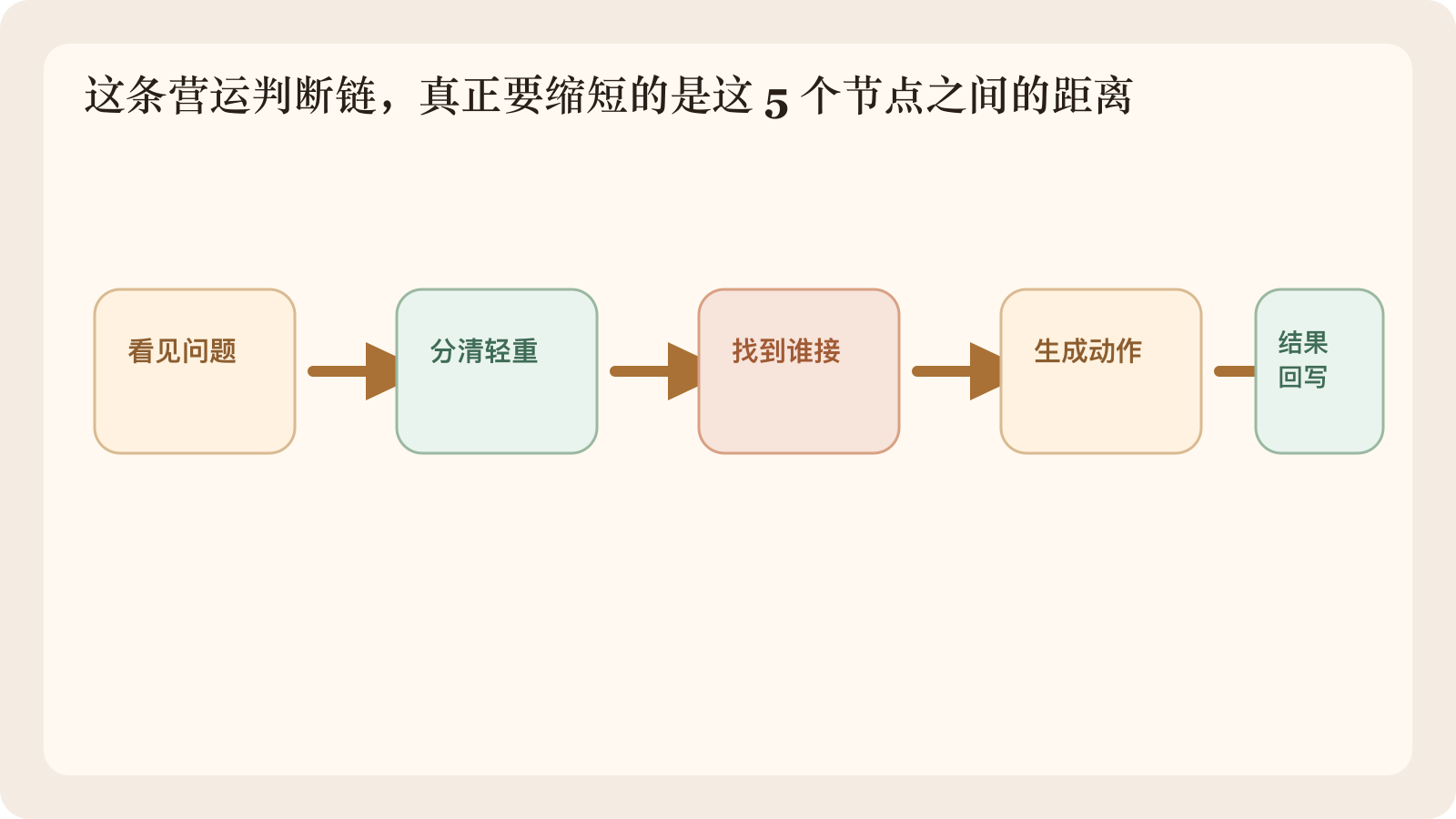
图 4:我们第一阶段真正要补短的,是“看见问题 -> 分清轻重 -> 找到谁接 -> 生成动作 -> 结果回写”这一段。
我们会拿什么来判断第一阶段到底值不值
第一次试点最怕的,不是功能少。
最怕的是功能做了一堆,却说不清价值。
所以如果这轮项目真的开做,我们不会拿“上线了几个模块”来汇报。
我们更可能只盯 4 个数:
- 首次响应时间有没有缩短
- 升级 / 路由准确率有没有提高
- 整改超时率有没有下降
- 同类问题复发率有没有下降
这 4 个数的意义在于,它们能直接回答管理层最关心的问题:
我们到底是在缩短经营判断链,还是只是多包了一层技术外壳。
这轮项目里,我们暂时不会做什么
真实落地里,克制比兴奋更重要。
至少在第一阶段,我们会明确不做下面这些事:
- 不先做
AI店长这种大角色叙事 - 不把排班、补货、投诉、巡店一次性全塞进第一期
- 不让 AI 直接替门店对外承诺
- 不跳过人工复核,把系统输出直接当最终结论
更稳的顺序应该是:
- 先跑通一条链
- 再扩成一类 workflow
- 最后才谈更高层协调
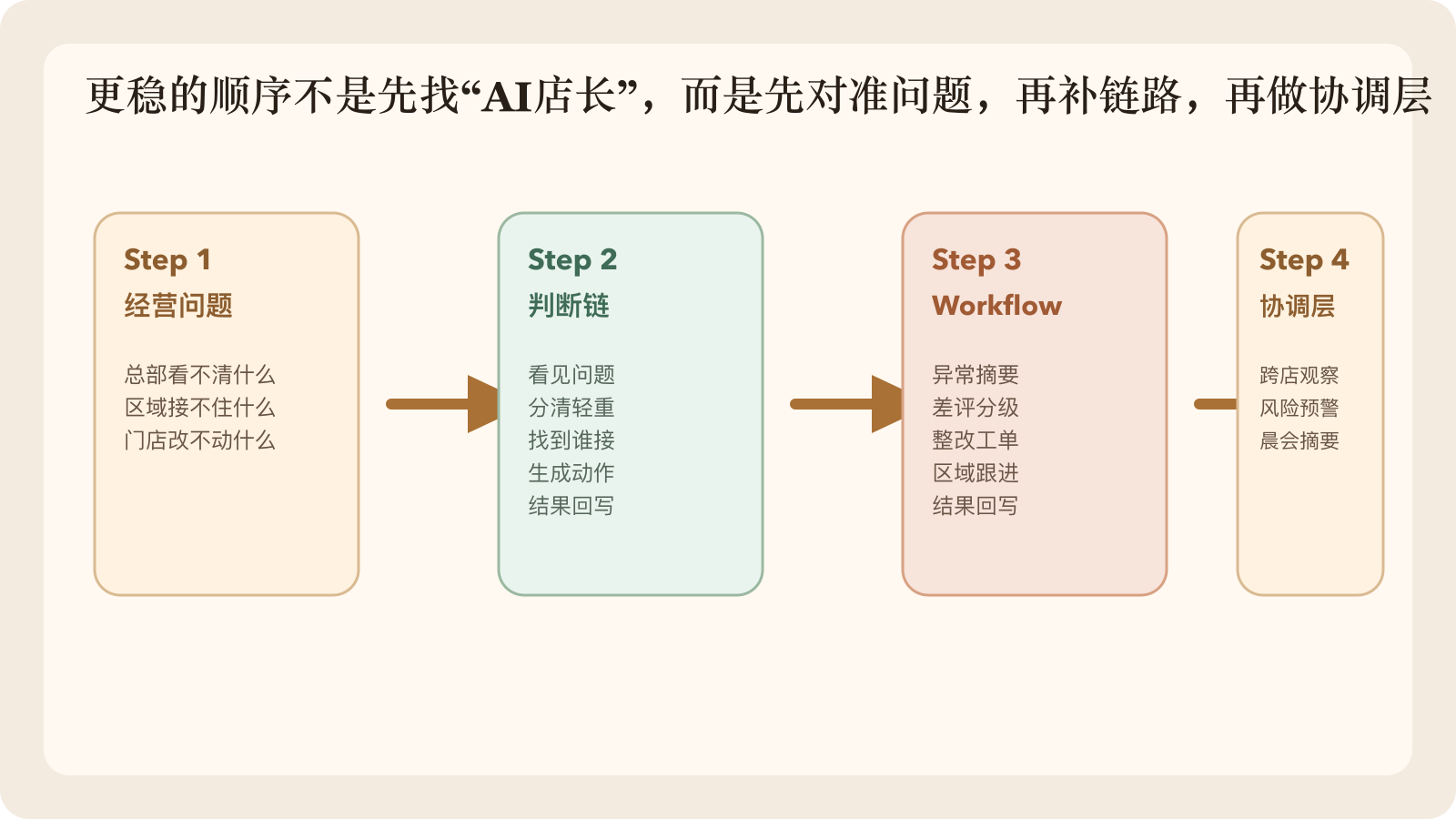
图 5:在这类项目里,我们更相信的顺序不是“先造角色”,而是“先补判断链,再接 workflow,最后才谈更高层协调”。
最后一句
如果下一次我们再进一家连锁餐饮企业,我大概率还是会先做同样的事。
不是先问:
“你们想不想做一个 AI店长?”
而是先问:
“把你们过去一周最头疼的问题拿出来看,哪条链今天最常断在总部、区域、门店之间?”
只要这个问题答出来,第一批该做的 AI,通常也就浮出来了。
对连锁餐饮来说,AI 落地真正的起点,往往不是一个更聪明的角色。
而是一条更短、更清楚、更能闭环的经营判断链。